


Credit: Tencent
On Tuesday, Tencent released HunyuanWorld-Voyager, a new open-weights AI model that generates 3D-consistent video sequences from a single image, allowing users to pilot a camera path to "explore" virtual scenes. The model simultaneously generates RGB video and depth information to enable direct 3D reconstruction without the need for traditional modeling techniques. However, it won't be replacing video games anytime soon.
The results aren't true 3D models, but they achieve a similar effect: The AI tool generates 2D video frames that maintain spatial consistency as if a camera were moving through a real 3D space. Each generation produces just 49 frames—roughly two seconds of video—though multiple clips can be chained together for sequences lasting "several minutes," according to Tencent. Objects stay in the same relative positions when the camera moves around them, and the perspective changes correctly as you would expect in a real 3D environment. While the output is video with depth maps rather than true 3D models, this information can be converted into 3D point clouds for reconstruction purposes.
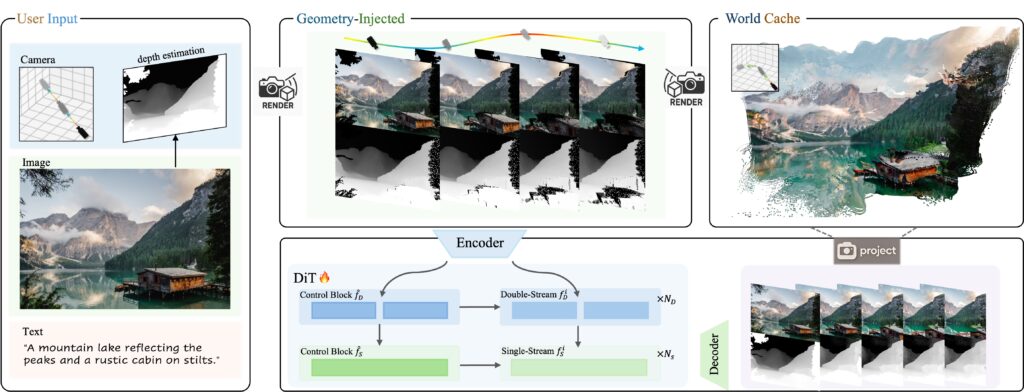
The system works by accepting a single input image and a user-defined camera trajectory. Users can specify camera movements like forward, backward, left, right, or turning motions through the provided interface. The system combines image and depth data with a memory-efficient "world cache" to produce video sequences that reflect user-defined camera movement.
A major limitation of all AI models based on the Transformer architecture is that they fundamentally imitate patterns found in training data, which limits their ability to "generalize," which means to apply those patterns to novel situations not found in the training data. To train Voyager, researchers used over 100,000 video clips, including computer-generated scenes from Unreal Engine—essentially teaching the model to imitate how cameras move through 3D video game environments.
Most AI video generators, like Sora, create frames that look plausible one after another without attempting to track or maintain spatial consistency. Notably, Voyager has been trained to recognize and reproduce patterns of spatial consistency, but with an added geometric feedback loop. As it generates each frame, it converts the output into 3D points, then projects these points back into 2D for future frames to reference.
This technique forces the model to match its learned patterns against geometrically consistent projections of its own previous outputs. While this creates much better spatial consistency than standard video generators, it's still fundamentally pattern-matching guided by geometric constraints rather than true 3D "understanding." This explains why the model can maintain consistency for several minutes but struggles with full 360-degree rotations—small errors in pattern matching accumulate over many frames until the geometric constraints can no longer maintain coherence.
The system utilizes two main parts working together, according to Tencent's technical report. First, it generates color video and depth information simultaneously, making sure they match up perfectly—when the video shows a tree, the depth data knows exactly how far away that tree is. Second, it uses what Tencent calls a "world cache"—a growing collection of 3D points created from previously generated frames. When generating new frames, this point cloud is projected back into 2D from the new camera angle to create partial images showing what should be visible based on previous frames. The model then uses these projections as a consistency check, ensuring new frames align with what was already generated.
The release adds to a growing collection of world generation models from various companies. Google's Genie 3, announced in August 2025, generates interactive worlds at 720p resolution and 24 frames per second from text prompts, allowing real-time navigation for several minutes. Mirage 2 from Dynamics Lab offers browser-based world generation, allowing users to upload images and transform them into playable environments with real-time text prompting. While Genie 3 focuses on training AI agents and isn't publicly available, and Mirage 2 emphasizes user-generated content for gaming, Voyager targets video production and 3D reconstruction workflows with its RGB-depth output capabilities.
Training with automated data pipeline
Voyager builds on Tencent's earlier HunyuanWorld 1.0, released in July. Voyager is also part of Tencent's broader "Hunyuan" ecosystem, which includes the Hunyuan3D-2 model for text-to-3D generation and the previously covered HunyuanVideo for video synthesis.
To train Voyager, researchers developed software that automatically analyzes existing videos to process camera movements and calculate depth for every frame—eliminating the need for humans to manually label thousands of hours of footage. The system processed over 100,000 video clips from both real-world recordings and the aforementioned Unreal Engine renders.
A diagram of the Voyager world creation pipeline.
Credit: Tencent
The model demands serious computing power to run, requiring at least 60GB of GPU memory for 540p resolution, though Tencent recommends 80GB for better results. Tencent published the model weights on Hugging Face and included code that works with both single and multi-GPU setups.
The model comes with notable licensing restrictions. Like other Hunyuan models from Tencent, the license prohibits usage in the European Union, the United Kingdom, and South Korea. Additionally, commercial deployments serving over 100 million monthly active users require separate licensing from Tencent.
On the WorldScore benchmark developed by Stanford University researchers, Voyager reportedly achieved the highest overall score of 77.62, compared to 72.69 for WonderWorld and 62.15 for CogVideoX-I2V. The model reportedly excelled in object control (66.92), style consistency (84.89), and subjective quality (71.09), though it placed second in camera control (85.95) behind WonderWorld's 92.98. WorldScore evaluates world generation approaches across multiple criteria, including 3D consistency and content alignment.
While these self-reported benchmark results seem promising, wider deployment still faces challenges due to the computational muscle involved. For developers needing faster processing, the system supports parallel inference across multiple GPUs using the xDiT framework. Running on eight GPUs delivers processing speeds 6.69 times faster than single-GPU setups.
Given the processing power required and the limitations in generating long, coherent "worlds," it may be a while before we see real-time interactive experiences using a similar technique. But as we've seen so far with experiments like Google's Genie, we're potentially witnessing very early steps into a new interactive, generative art form.
-
 C114 Communication Network
C114 Communication Network -
 Communication Home
Communication Home
