

If you're evaluating voice cloning for a product or media pipeline, the real question isn't "can AI copy a voice?" It's how the system learns a voice safely, keeps it consistent, and produces usable audio in real-world conditions—different scripts, different emotions, different pacing, different environments.
That's where an enterprise-grade AI voice workflow matters. Voice cloning is not a single button. It's a structured process: collect the right audio, extract the "voice identity," train or adapt a model, and then generate speech while controlling quality and risk.
Below is how it works—clearly and step by step.
Voice Cloning in One Simple Idea
A cloned voice is not a recording of someone.
It's a voice model that learns patterns:
- how a person pronounces sounds
- their pitch range and typical intonation
- their rhythm and pacing
- the "texture" of their voice (timbre)
Then the model can say new text in a similar voice—without the person recording those lines.
Think of it like building a digital musical instrument:
- recordings are "samples"
- training is "tuning the instrument"
- generated speech is "playing new notes"
The Full Pipeline (No Jargon, Just the Truth)
Audio → Clean audio → Voice features → Voice model → Generated speech → QA + delivery
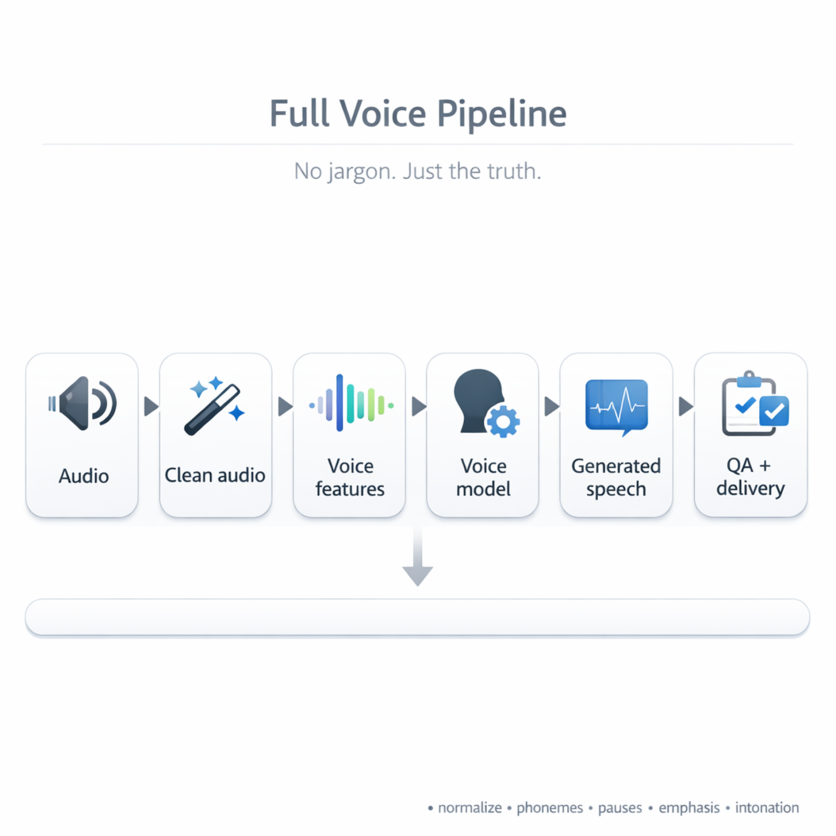
Let's walk through each stage.
1. Collecting Voice Data: The Input Decides the Output
Voice cloning starts with audio of the target speaker. The quality of that audio matters more than most people expect.
What "good" training audio looks like
- clear speech (no loud background noise)
- consistent microphone and room (or at least not chaotic)
- enough variety in sounds (not just "hello hello hello")
- ideally different sentence shapes (questions, statements, longer phrases)
Why this stage is a common B2B pain
Teams often bring:
- podcast audio with music
- Zoom calls with compression artifacts
- old interviews with crowd noise
- footage with overlapping speakers
Can you clone a voice from messy audio? Sometimes.
Will it be stable and production-ready? Often no.
A practical mindset: voice cloning is like training a chef. If you only give them junk ingredients, the dish will taste... like junk.
2. Audio Cleaning: Separating the Voice from the Mess
Before the model "learns the voice," the system usually cleans the audio:
- removes long silences
- reduces noise (within reason)
- normalizes loudness
- cuts out other speakers
- splits audio into usable segments
This step doesn't "make it perfect,"but it makes the training data consistent. Consistency is what prevents a clone that sounds different across sentences.
B2B pain, this prevents the voice sounds good in one line and weird in the next because training data was inconsistent.
3. Feature Extraction: Turning Audio into "Voice Fingerprints"
Here's the key mental model:
The system doesn't store the voice as raw audio.
It extracts features—numbers that represent the voice.
These features capture things like:
- timbre (voice color)
- articulation (how consonants/vowels are shaped)
- pitch behavior (not exact pitch, but patterns)
Modern systems often use embeddings (think: a compact "voice signature") to represent the speaker identity.
You can imagine it like face recognition:
- the system doesn't keep your photo as-is
- it converts it into a mathematical representation
- then matches or reproduces characteristics
Same idea for voices—except the goal is generation, not detection.
4. Modeling Approach: How Cloning Is Actually Built
There are a few common ways to create a cloned voice. You don't need the math—just the differences.
A. Training a dedicated voice model
This is like building a custom voice from the ground up. It can achieve high similarity and strong consistency, but usually needs more data and setup.
B. Voice adaptation (fine-tuning)
Start with a strong base TTS model and adapt it to the target voice. Often, a practical balance between quality, time, and data requirements.
C. Speaker-conditioning (using a voice embedding)
Some systems can generate speech in a target voice by providing a speaker embedding. This can be fast, but quality and control depend on the underlying model and training.
B2B takeaway: "voice cloning" isn't one method. Ask what approach is used because it affects:
- how much data you need
- how stable the voice will be
- how controllable it is in production
5. Text-to-Speech Generation: Making the Voice Say New Words
Once the system has learned the speaker identity, it generates speech similarly to modern TTS:
- Text is normalized (numbers, abbreviations, dates)
- It's converted into a pronunciation plan
- Prosody is planned (pauses, emphasis)
- An acoustic model produces an audio "blueprint"
- A vocoder renders the final waveform
The difference is: the voice identity is locked to the cloned speaker.
So, when you type:
"Your account is now active."
The system outputs that sentence in the cloned voice—even if the speaker never recorded those exact words.
6. Quality Control: The Part Most "Quick Demos" Skip
In real products, the question becomes:
How do we make the output reliably good?
Teams typically check:
- pronunciation accuracy (brand terms, names)
- artifacts (buzzing, metallic sounds, glitches)
- consistency (does it drift across long scripts?)
- emotional fit (too flat? too excited?)
- intelligibility (can users understand it clearly?)
This is also where you decide what's acceptable:
- for internal drafts, you may tolerate minor artifacts
- for film, ads, or public-facing UX, you usually won't
B2B pain this prevents: "It worked in testing, but sounds off in real content."
7. Safety, Consent, and Rights: The Enterprise Reality
In B2B, voice cloning always triggers risk questions:
- Do we have permission to use this voice?
- What can be generated and by whom?
- Can we prove consent and licensing?
- Are there guardrails to prevent misuse?
This is why ethical, consent-based workflows matter. It's not "extra."It's often what procurement and legal teams care about first—because brand risk is expensive.
Respeecher's positioning around licensed, ethical voice use is relevant here: enterprise buyers don't just want a clone—they want a system that fits governance and trust requirements.
A Concrete Example (So It Becomes Obvious)
Let's say you want a cloned voice for a product onboarding video series.
What you provide:
- 30–60 minutes of clean voice recordings (ideally)
- a glossary of your product terms (brand pronunciation)
- your script
What the system does:
- cleans and segments the audio
- learns the speaker identity (voice signature)
- generates speech for your script in that voice
- you QA the output and adjust pronunciations or pacing
What you get:
- consistent narration without repeated recording sessions
- faster iteration when scripts change
- a voice that stays stable across months of new content
That's the business value: speed + consistency, not novelty.
The Simplest Summary
AI voice cloning works by taking recordings of a speaker, cleaning the audio, extracting a compact "voice identity," and using that identity inside a text-to-speech system to generate brand-new speech in the same voice—then validating quality and applying governance for safe use.
Ready to clone a voice the right way?
If you're exploring voice cloning for customer-facing content, a voice product, or a media pipeline, the fastest path is to start with a clean, consent-based workflow and test against real production scripts—not toy examples.
Respeecher can help you validate feasibility, define the right data requirements, and build a reliable voice cloning setup that fits enterprise needs—from voice quality and pronunciation control to governance and safe deployment. If you're looking for a production-grade AI voice solution, reach out to the Respeecher team to discuss your use case and the best next step.
-
 C114 Communication Network
C114 Communication Network -
 Communication Home
Communication Home
