

It's easy to ship an AI demo and painfully hard to ship an AI product that survives real usage. Models and GPUs are not the bottleneck anymore. The real work is product: picking problems that actually move the needle, choosing the right abstraction, and designing for performance, integration, security, ethics, and collaboration from day one.
Shankar Krishnan, a product leader at AWS, offers a practical playbook based on his extensive experience building and supporting large-scale AI products—with the main focus kept on how to build.

Shankar Krishnan
Disclaimer: The views expressed in this column are solely those of Shankar Krishnan and do not necessarily reflect the practices of any of his current or former employers.
Start with Problems That Actually Matter
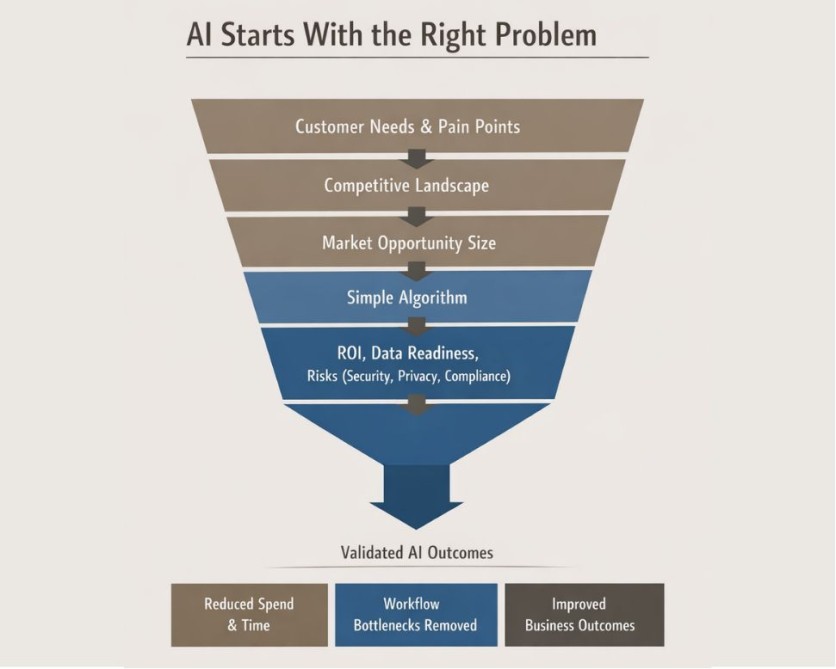
Before building any model, you need to have a problem that justifies AI at all. That starts with proper discovery: understanding customer needs and pain points, the competitive landscape, and the potential market opportunity size.
The goal is to prioritize problems where AI can:
- reduce clear spending and wasted time
- remove bottlenecks in existing workflows
- improve hard business outcomes (CX, productivity, or process efficiency)
At this stage, you explicitly ask: Can a simple algorithm or workflow change solve this? Is there enough funding and an adequate return on investment? Do we have the right level of data, and what are the key risks (security, privacy, compliance), and the timeline in which this needs to be solved?
In the voice space, this thinking led to products like automatic speech recognition (ASR) models from various companies being designed for use in industries where the stakes are obvious: healthcare, financial services, telecom, insurance, travel, hospitality, and public safety. Exactly because it was intended for real, high-value use cases from the start.
Choosing the Right Level of Abstraction
Once you know what you're solving, you must decide how customers will consume it:
- low-level APIs
- higher-level flows / SDKs
- full end-to-end solutions
The right level of abstraction depends on four key things:
- the target persona (enterprise developer vs. non-technical business user)
- the monetization strategy (where the product can capture value)
- how you create a sustainable, differentiated moat (infrastructure vs. workflow vs. UX)
- in-house capabilities and distribution strategy
For a B2B product targeting developers at enterprises, APIs are often the best choice; they let teams embed your capabilities into their own systems. That's why transcription and speech models are exposed as API services. But when the target is a retail consumer, it's better to ship a simple application.
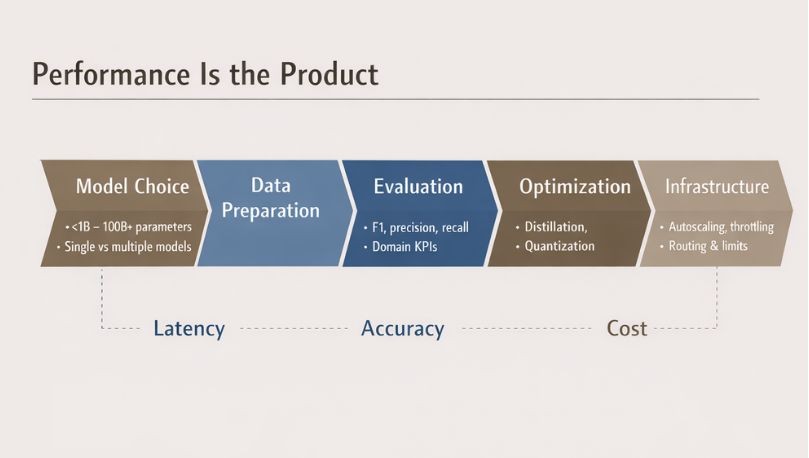
Designing for Performance and Cost Balance
Performance isn't a "later" concern; it is the product. To keep latency, accuracy, and cost controllable from day one, you deliberately work through several layers:
- Model choice. Select model sizes that fit the job, from less than 1B to more than 100B+ parameters, and decide whether you need deep neural networks, transformer-based architectures, or multiple models in a pipeline. Larger models may be more accurate, but they drive up training and inference costs.
- Data preparation. Clean, pre-process, and properly label data so the model sees real-world edge cases.
- Evaluation. Benchmark on metrics like F1, precision, and recall, plus domain-specific KPIs, and use them to guide optimization.
- Optimization. Techniques such as knowledge distillation and quantization reduce model size and compute without drastically compromising performance.
- Infrastructure. Autoscaling, API throttling and limiting, and smart model routing ensure the system behaves predictably under load.
Balancing Small and Large Models
Choosing between small and large models is a product decision, not just a research one. It depends on:
- type and complexity of use cases
- budget for inference and available compute capacity
- degree of customization and fine-tuning needed
Smaller models are better suited for targeted, high-frequency tasks that don't require complex reasoning: for example, document summarization, simple classification, or telemetry analysis that must run with low-latency and cost-efficient inference, sometimes at the edge. They can be fine-tuned quickly with domain-specific data (e.g., healthcare) and redeployed frequently.
Large language models are more suited for use cases such as a chatbot that require complex multi-step reasoning, heavy data analysis, content creation, or a disparate set of tasks to be performed. Further, larger models require higher computing power and therefore work best for use cases in which compute is not necessarily a constraint.
Security, Privacy, and Compliance by Design
AI products almost always handle sensitive data. If security, privacy, and compliance aren't built in from the beginning, they block or kill deals later.
The baseline includes:
- collecting only the data you need
- retaining data in compliance with regulations like GDPR
- role-based access control, plus authentication using OAuth, JSON Web Tokens (JWT), and multi-factor authentication where appropriate
- encrypting data at rest with standards like AES and in transit with TLS or mutual TLS
- comprehensive monitoring and logging so you can detect, investigate, and remediate incidents quickly
Designing for security and compliance from day one is what lets AI products get quickly adopted in regulated industries without becoming a liability.
Operationalizing Ethical AI
To make ethical AI practical, you treat it as a process, not a slogan.
A central group—spanning legal, privacy, product, engineering, ethics, and compliance—defines concrete standards that every AI feature must meet. Those standards then guide:
- The data used to train models need to be diverse and representative enough of target customers so that it is devoid of ethical issues, resulting in higher accuracy. This can be done by properly labeling the data, sanitizing it of any sensitive information, and cleaning the data to remove any biases.
- As the model is designed, key tradeoffs being made to incorporate ethical AI into products needs to be captured. These tradeoffs should be also transparently shared internally and with customers so that everyone is aware of the tradeoffs and limitations.
- As the model is trained, it needs to be tested against a comprehensive set of metrics, such as bias and toxicity, to ensure that it does not skew or discriminate against certain groups. This testing can be supported by techniques such as adversarial testing and adversarial training.
- Once the model has been developed, you can use explainability techniques such as Local Interpretable Model-agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP) to better understand its behaviour.
Aligning Product, Engineering, ML, and Go-to-Market
Effective collaboration across key stakeholders needs to happen throughout the entire product lifecycle.
During the ideation phase, product managers should work closely with go-to-market (GTM) teams to identify the most important customer problems to solve. Product teams can use AI tools such as Gemini and ChatGPT to conduct market research and synthesize qualitative and quantitative feedback from customers.
In the prototyping phase, the product team partners with design, engineering, and ML teams to brainstorm and evaluate solution options. Product can "vibe code" early concepts using AI-assisted tools like Base44 and Replit to quickly create lightweight prototypes, share solution designs, and validate that the approach is technically feasible. Once a vibe-coded solution exists, GTM teams can collect feedback from a small set of customers to confirm that it addresses real pain points.
During the product development phase, engineering and ML teams demo key functionality on a regular cadence so the product can provide timely feedback on features and usability. In parallel, product, engineering, and ML jointly define the evaluation framework and success metrics for the product, while the engineering team is responsible for instrumenting and maintaining this measurement layer.
As you approach launch, the product gathers pricing-related inputs from engineering, such as operating costs and performance characteristics of AI features (for example, latency and accuracy). Based on this, the product collaborates with GTM to refine the value proposition, marketing strategy, target customer segments, and a high-level plan to achieve near-term revenue goals.
Post-launch, feedback from GTM teams, customers, and support tickets can be analysed using AI tools, and the resulting insights are fed back to engineering and ML teams to prioritize improvements and guide the next iterations of the product.
On top of that, you need clear metrics. They typically fall into four categories:
- Customer adoption: active users (daily/weekly/monthly), average session duration, retention at 30/60/90 days, customer mix by size and location.
- Business metrics: subscription revenue, average discount, average selling price, new product revenue, churn and retention, cross-sell and up-sell revenue, pipeline size and value, acquisition cost, payback period, and lifetime value.
- Customer satisfaction: Net Promoter Score (NPS), Customer Satisfaction (CSAT), volume, and type of feature requests.
- Operational efficiency and reliability: uptime, availability, average time to resolve bugs, average time to launch high-priority features, and, for AI specifically, latency, cost, and accuracy.
Alongside these, you define a single north-star metric that captures overall success. When your team can say something like, "this new AI model improved accuracy by 20%, lowered latency by 30%, cut operating cost 2x," you're no longer just shipping models. You're running an AI product that actually scales.
-
 C114 Communication Network
C114 Communication Network -
 Communication Home
Communication Home
