


Credit: Getty Images
Ever wonder why ChatGPT slows down during long conversations? The culprit is a fundamental mathematical challenge: processing long sequences of text requires massive computational resources, even with the efficiency tricks that companies have already deployed. While US tech giants can afford to throw more hardware at the problem, Chinese AI company DeepSeek, which is cut off from a steady supply of some advanced AI chips by export restrictions, has extra motivation to squeeze more performance from less silicon.
On Monday, DeepSeek released an experimental version of its latest simulated reasoning language model, DeepSeek-V3.2-Exp, which introduces what it calls "DeepSeek Sparse Attention" (DSA). It's the company's implementation of a computational technique likely already used in some of the world's most prominent AI models. OpenAI pioneered sparse transformers in 2019 and used the technique to build GPT-3, while Google Research published work on "Reformer" models using similar concepts in 2020. (The full extent to which Western AI companies currently use sparse attention in their latest models remains undisclosed.)
Despite sparse attention being a known approach for years, DeepSeek claims its version achieves "fine-grained sparse attention for the first time" and has cut API prices by 50 percent to demonstrate the efficiency gains. But to understand more about what makes DeepSeek v3.2 notable, it's useful to refresh yourself on a little AI history.
DeepSeek made waves in January when its R1 simulated reasoning model reportedly matched OpenAI's o1 performance while costing only $6 million to train, and its chat app briefly topped the iPhone App Store, surpassing ChatGPT. All eyes are on the company that has given some of America's leading AI labs a run for their money.
The attention bottleneck
In AI, "attention" is a term for a software technique that determines which words in a text are most relevant to understanding each other. Those relationships map out context, and context builds meaning in language. For example, in the sentence "The bank raised interest rates," attention helps the model establish that "bank" relates to "interest rates" in a financial context, not a riverbank context. Through attention, conceptual relationships become quantified as numbers stored in a neural network. Attention also governs how AI language models choose what information "matters most" when generating each word of their response.
Calculating context with a machine is tricky, and it wasn't practical at scale until chips like GPUs that can calculate these relationships in parallel reached a certain level of capability. Even so, the original Transformer architecture from 2017 checked the relationship of each word in a prompt with every other word in a kind of brute force way. So if you fed 1,000 words of a prompt into the AI model, it resulted in 1,000 x 1,000 comparisons, or 1 million relationships to compute. With 10,000 words, that becomes 100 million relationships. The cost grows quadratically, which created a fundamental bottleneck for processing long conversations.
Although it's likely that OpenAI uses some sparse attention techniques in GPT-5, long conversations still suffer performance penalties. Every time you submit a new response to ChatGPT, the AI model at its heart processes context comparisons for the entire conversation history all over again.
Of course, the researchers behind the original Transformer model designed it for machine translation with relatively short sequences (maybe a few hundred tokens, which are chunks of data that represent words), where quadratic attention was manageable. It's when people started scaling to thousands or tens of thousands of tokens that the quadratic cost became prohibitive.
Sparse attention works differently. Instead of checking every word against every word, it only examines a subset of word relationships that the model determines are most relevant. For example, when processing word number 5,000 in a document, the model might only check its relationship with 100 carefully selected earlier words rather than all 4,999 preceding words.
DeepSeek's model gains the ability to determine which relationships to prioritize through training, using what DeepSeek calls a "lightning indexer." As laid out in DeepSeek's paper on the new model, this small neural network component scores the relevance between word pairs and selects the top 2,048 most important connections for each word, though the paper doesn't fully explain how this indexer makes its decisions. DeepSeek claims its implementation can identify which connections to skip without degrading the model's understanding of the overall text.
Early benchmarks show promise
DeepSeek-V3.2-Exp builds on the company's previous V3.1-Terminus model but incorporates DeepSeek Sparse Attention. According to the company's benchmarks, the experimental model performs comparably to its predecessor even while using sparse attention.
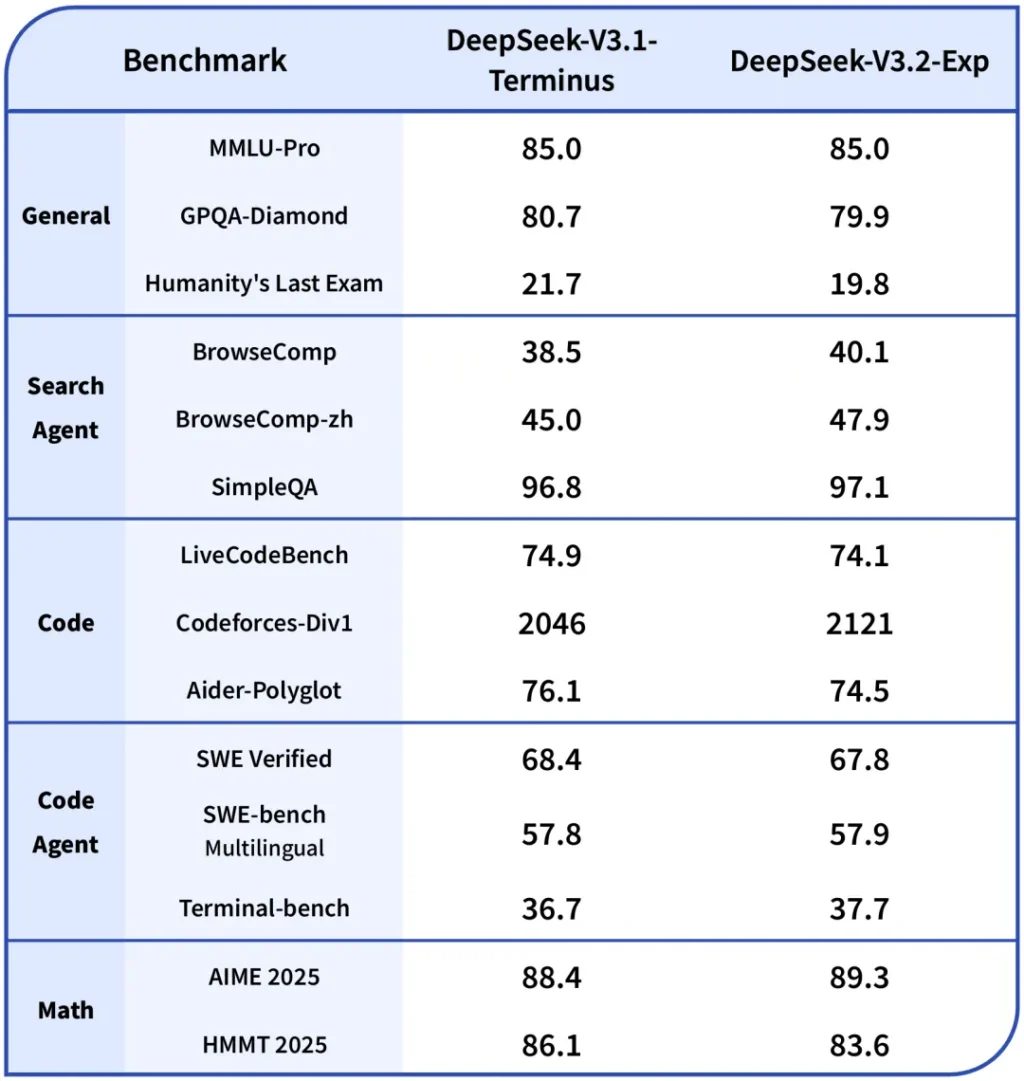
Credit: DeepSeek
Notably, unlike OpenAI and Anthropic's high-end AI models, the release includes open source components under the MIT License and open weights, allowing other researchers to build on the work.
TechCrunch reports that preliminary testing by DeepSeek found that API costs could be reduced by as much as half in long-context situations. However, the benchmarks come from DeepSeek's own testing, and third-party researchers haven't had time to independently verify the performance claims or validate the efficiency improvements. But if the research pans out, improvements to the sparse attention technique could dramatically reduce AI inference costs over time.
-
 C114 Communication Network
C114 Communication Network -
 Communication Home
Communication Home
