


MMD Creative | Shutterstock
Abstract
This article shares what we learned while building GreenBull, an AI system for real-time investment insights. Instead of focusing on the tool itself, it looks at the design choices that made the system more accurate, flexible, and reliable. We explain why large language models alone aren't enough when working with structured data or complex logic, and how a modular setup (combining databases, semantic search, and LLMs) can lead to better results. The lessons apply to anyone building AI systems where clear answers and trust matter.
LLMs are great at talking. Databases are great at counting.
The challenge is getting them to work together without stepping on each other's toes.
That was the problem we ran into while building GreenBull, a system built to surface real-time insights from stock prices, earnings reports, and financial news. At first, we let a large language model take the lead. It sounded smart, but the numbers didn't always hold up. Tables got misread, calculations went sideways, and context was easy to lose.
So we changed course.
We designed a modular setup where each part plays to its strengths. Databases handle structured data. A vector engine pulls in unstructured content. The LLM handles reasoning and explanation.
What follows is a closer look at how that architecture came together, and what it taught us about building AI systems that stay accurate, scalable, and clear even when the questions get complex.
Why We Needed More Than an LLM
We started GreenBull as an experiment: could a large language model, given access to the right sources, serve up real-time, investment-grade insights?
The early results were mixed. The LLM was excellent at summarizing text, correlating events, and even writing explanations. But when it came to numerical accuracy, real-time queries, or comparing structured data across timeframes, things broke down.
What we learned quickly:
- LLMs hallucinate numbers when asked to reason over structured datasets like earnings tables or financial statements.
- They're limited by context windows, especially when dealing with long 10-K filings or side-by-side stock comparisons.
- They're not built to aggregate or filter across millions of rows, something a traditional SQL query handles instantly.
To move forward, we needed a hybrid approach: one that used structured data systems for precision, vector databases for semantic memory, and LLMs for language understanding and articulation, each component playing to its strength.
That realization became the foundation of everything that followed: from our choice of architecture to how agents handle routing, to how we treat unstructured news and earnings reports differently from raw stock data.
Designing the Flow: Turning Raw Data into Answers

GaudiLab | Shutterstock
When building a real-time system for investment insights, we had to think carefully about how different types of data move through the pipeline. Our goal was to create a setup that could handle structured data like prices and earnings, as well as unstructured inputs like news headlines and filings, without slowing down or getting confused.
We used Google Cloud Platform to run scheduled jobs that pull data from three primary sources:
- Stock APIs like Yahoo Finance and Alpha Vantage
- Earnings reports and filings from the SEC
- News and social media content from places like Bloomberg, CNBC, and Reddit
Each of these inputs is handled separately. Numbers and charts go into a traditional SQL database. Articles and long reports are summarized and stored in a vector database built for fast search.
Keeping these streams apart lets us optimize how each one is processed. It also makes the whole system easier to update, scale, and fix when something breaks.
Once the data is in place, we use a set of agents to handle the user's query. One pulls structured facts. Another searches for relevant text. A final layer puts everything together into a response.
The key lesson here is that instead of asking a language model to do everything, we split the work across tools that each do one thing well. That made the system faster, easier to maintain, and more reliable when it mattered.
System Architecture
The design behind GreenBull prioritizes modularity, speed, and clarity. Here's how data moves through the system, from external sources to the final user output.
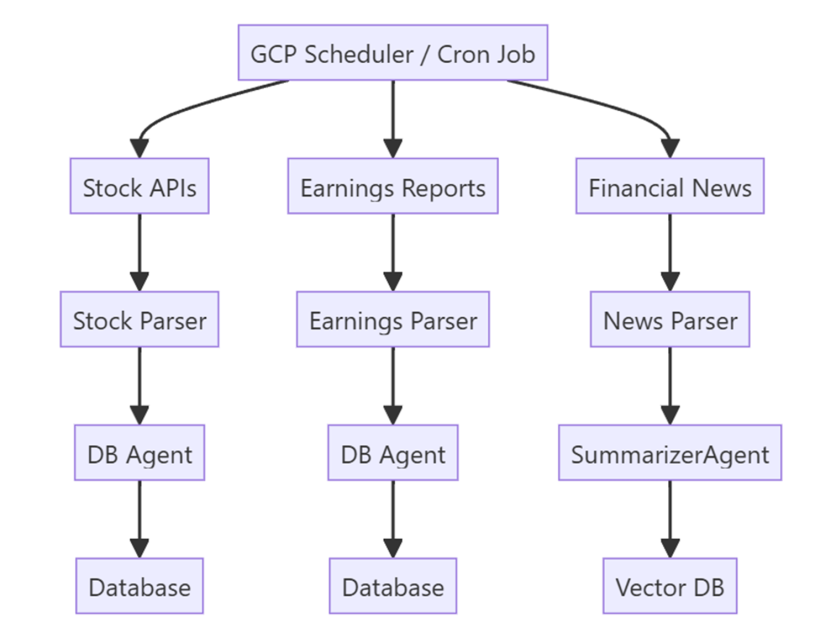
Diagram 1: Data ingestion flow showing how external sources are parsed and stored.
This setup is intentional. Unlike a monolithic LLM that tries to do everything with one prompt, GreenBull separates logic across agents:
| Component | Responsibility | Benefit |
| Orchestrator Agent | Plans, tasks, and sequences | Adds logic and traceability |
| DB Agent | Queries structured stock data | Ensures accuracy and factual responses |
| Research Agent | Pulls semantically similar documents | Handles unstructured data effectively |
| Summarizer Agent | Extracts key info from filings and news | Enables fast, context-rich responses |
| Sentiment Engine | Scores tone and emotional valence | Flags bullish or bearish signals |
| Answer Generator | Formats responses for users | Makes outputs actionable and easy to navigate |
Together, these components form a system that is both flexible and reliable. By distributing tasks across specialized agents, GreenBull can process large volumes of data efficiently while preserving accuracy, context, and responsiveness at every step.
Workflow: How a Query Is Handled
Once a user submits a query, GreenBull breaks it down, routes it through the right agents, and returns a complete, contextual response. The flow below outlines how each part of the system works together to analyze both structured and unstructured data in parallel.
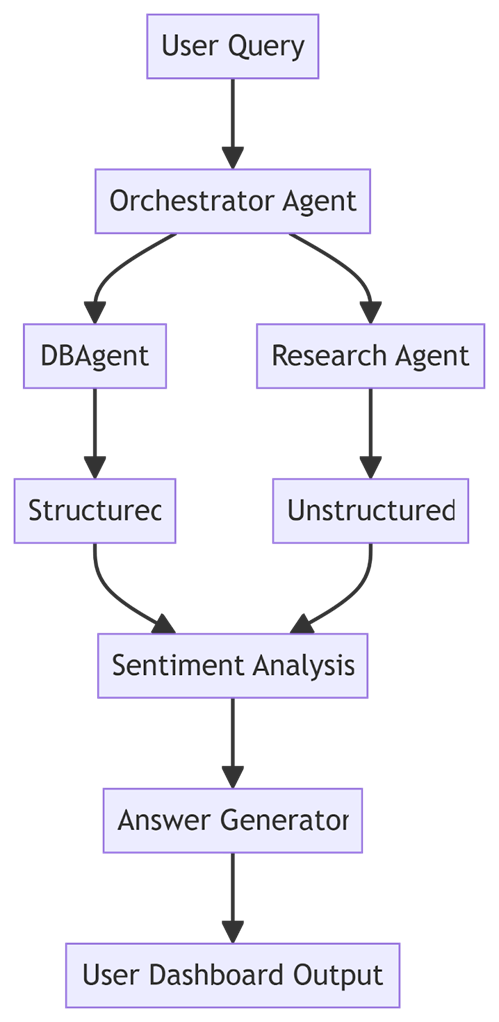
Diagram 2: Step-by-step breakdown of how GreenBull processes investor questions using parallel agents.
Apple Example: A user asks, "What are the key takeaways from Apple's Q2 earnings?" GreenBull responds with a quick breakdown: revenue is up 7%, margins narrowed by 1.2%, and guidance remains flat. It includes a comparison to Q1, a shift in sentiment from analysts, and a link to the source.
Tesla Example: Another user types, "Should I be worried about recent news on Tesla?" The system pulls financial data, real-time headlines, and sentiment scores to provide a grounded view, eliminating the need for extra digging or guesswork.
Why a Modular Agentic System?
Here's what we ran into when testing early prototypes that relied on a single LLM:
- They couldn't properly ground answers in structured data like financial statements
- Long queries, especially those with embedded PDFs or tables, ran into token limits and hallucinated numbers
- It wasn't possible to follow up or refine a query mid-conversation. The model's understanding was limited to a single prompt at a time.
So we split the system into modules.
Now, each agent does what it's best at. If the user's request primarily involves numbers, the DB Agent handles it. If it's contextual, like comparing sentiments or summarizing news, the Research Agent takes over. Then, the Orchestrator stitches everything together into a coherent, helpful answer. That's much closer to how fundamental analysts work.
Examples of GreenBull in Action
GreenBull adapts to a wide range of investor needs. The table below shows how different users might interact with the system based on their goals and investment styles.
| Investor Type | Scenario | GreenBull Delivers |
| Beginner | Wants to track 3 to 5 stocks safely | Watchlist plus cautious-mode suggestions |
| Retiree | Income-focused portfolio | High-yield, low-volatility dividend picks |
| Analyst | Tracks market mood in the tech sector | Sentiment dashboard with score breakdown |
| Day trader | Needs second-by-second updates on Tesla | Live data stream plus media sentiment scoring |
Whether someone's focus is safety, income, trends, or speed, the system is built to meet them where they are and deliver insights they can act on.
Personalized Risk Modes
Every investor thinks differently about risk. That's why GreenBull adapts its suggestions based on your selected style:
| Risk Level | Suggests |
| Cautious | Dividend stocks, low-volatility, blue chips |
| Moderate | Balanced mix of growth and value equities |
| Aggressive | Small caps, high-beta stocks, sector rotation |
The backend logic adjusts accordingly, filtering candidates through volatility, dividend yield, earnings stability, and recent news.
Built for Scale, Built for Clarity
Because the architecture is modular, it's easy to extend. Want to add a new ETF analyzer? Just spin up a new agent. Do you need to switch out the vector database? Replace Pinecone with FAISS without modifying the rest.
This design also improves transparency. Each agent logs its process, including the query it ran, the source it used, and its scoring of relevance.
That traceability isn't just helpful for debugging; it also supports explainability and auditability, both of which are essential in regulated financial environments. Investors, teams, and compliance reviewers can view the process by which a response was generated, the data used, and the rationale behind specific recommendations.
Lessons from Building a Smarter AI System
Working on GreenBull forced us to confront the real limits of large language models. They're great at reasoning and communication, but not at precision, aggregation, or memory across steps. Relying on them alone created more problems than it solved.
What worked better was splitting responsibilities. Let traditional tools handle what they're good at (structured queries, real-time updates, semantic retrieval), and let the LLM focus on interpreting, connecting, and explaining.
This modular, agent-based approach proved to be more scalable, transparent, and better aligned with how real users ask questions. And while we built it in the context of investing, the same structure can apply anywhere complex decisions depend on both data and context.
About the Author

Shashank Shivam
Shashank Shivam is a senior software engineer specializing in AI, cloud infrastructure, and large-scale data systems. With a proven track record at Oracle and extensive experience in machine learning, natural language processing, and computer vision, he focuses on building intelligent systems that transform complexity into clarity. His work bridges advanced technical design with real-world impact, particularly in areas where automation and decision-making intersect.
-
 C114 Communication Network
C114 Communication Network -
 Communication Home
Communication Home
